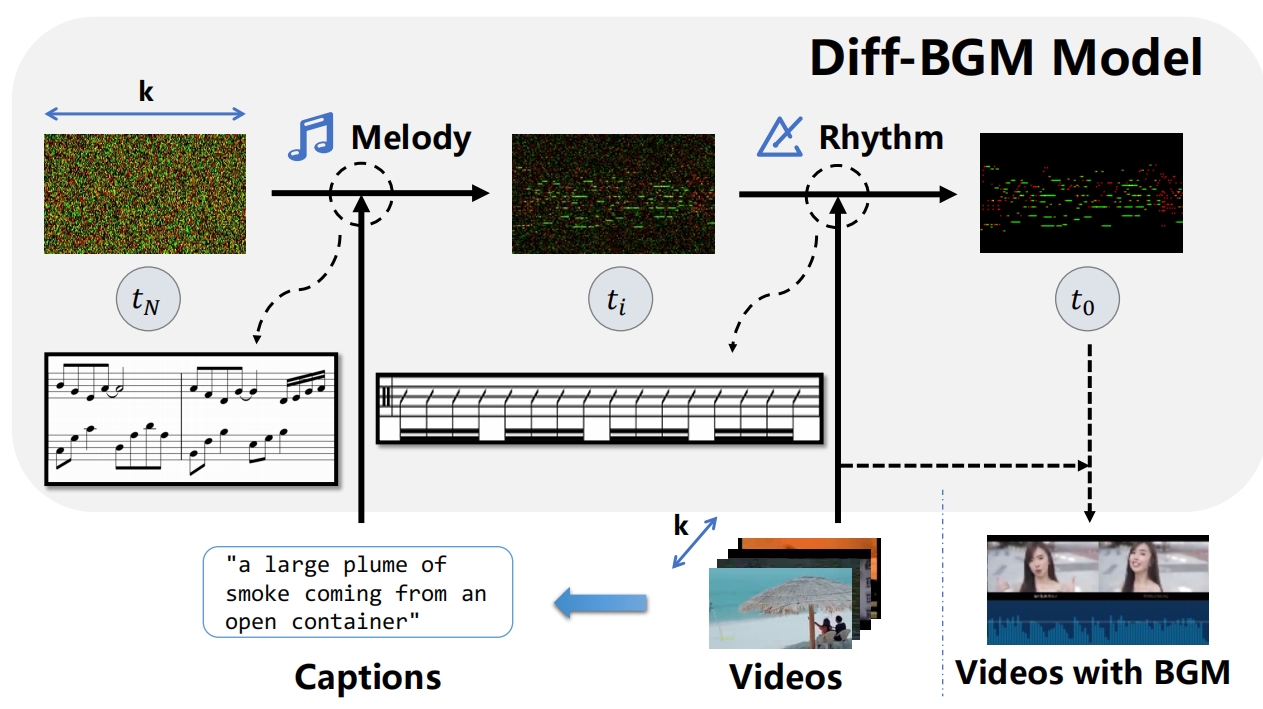
When editing a video, a piece of attractive background music is indispensable. However, video background music generation tasks face several challenges, for example, the lack of suitable training datasets, and the difficulties in flexibly controlling the music generation process and sequentially aligning the video and music. In this work, we first propose a high-quality music-video dataset BGM909 with detailed annotation and shot detection to provide multi-modal information about the video and music. We then present evaluation metrics to assess music quality, including music diversity and alignment between music and video with retrieval precision metrics. Finally, we propose the Diff-BGM framework to automatically generate the background music for a given video, which uses different signals to control different aspects of the music during the generation process, i.e., uses dynamic video features to control music rhythm and semantic features to control the melody and atmosphere. We propose to align the video and music sequentially by introducing a segment-aware cross-attention layer. Experiments verify the effectiveness of our proposed method. The code and models are available here .
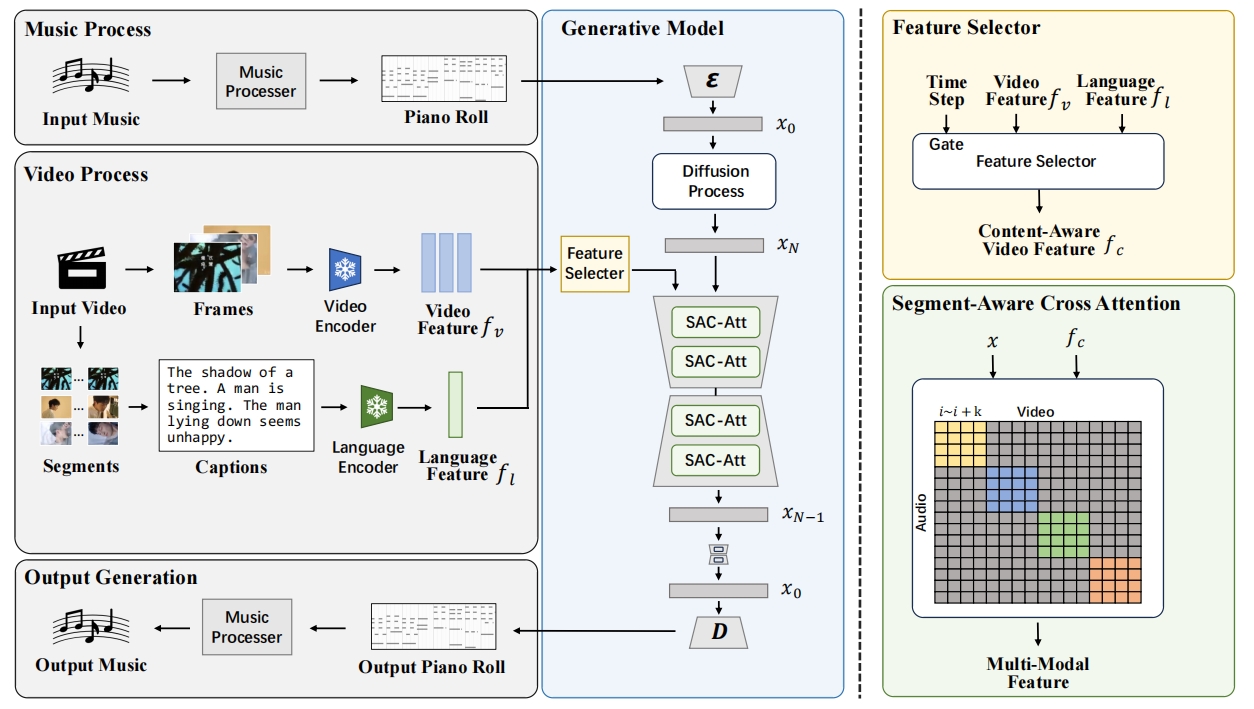
We process the input music and video, gain piano rolls to represent the music and extract visual features to represent the videos. In order to get richer semantic information, we segment the video and generate captions then extract language features. The backbone of the generation model is a diffusion model, with the processed visual and language features as conditions to guide the generation process. We propose a feature selector to choose features to control the generation process. And to better align the timing of the music and video, we design segment-aware cross-attention layer to grasp the timing feature in different modalities.
@misc{li2024diffbgm,
title={Diff-BGM: A Diffusion Model for Video Background Music Generation},
author={Sizhe Li and Yiming Qin and Minghang Zheng and Xin Jin and Yang Liu},
year={2024},
eprint={2405.11913},
archivePrefix={arXiv},
primaryClass={cs.CV}
}